Recent Publications

Tanmay Basu
The DepSign-LT-EDI-ACL2022 shared task
focuses on early prediction of severity of depression over social media posts. The BioNLP
group at Department of Data Science and Engineering in Indian Institute of Science Education and Research Bhopal (IISERB) has
participated in this challenge and submitted
three runs based on three different text mining models. The severity of depression were
categorized into three classes, viz., no depression, moderate, and severe and the data to
build models were released as part of this
shared task. The objective of this work is to
identify relevant features from the given social media texts for effective text classification. As part of our investigation, we explored
features derived from text data using document embeddings technique and simple bag
of words model following different weighting schemes. Subsequently, adaptive boosting, logistic regression, random forest and support vector machine (SVM) classifiers were
used to identify the scale of depression from
the given texts. The experimental analysis on
the given validation data show that the SVM
classifier using the bag of words model following term frequency and inverse document
frequency weighting scheme outperforms the
other models for identifying depression. However, this framework could not achieve a place
among the top ten runs of the shared task. This
paper describes the potential of the proposed
framework as well as the possible reasons behind mediocre performance on the given data
View
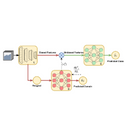
Vinod K. Kurmi, Rishabh Sharma, Yash Vardhan Sharma, Vinay P Namboodiri
Bias mitigation in machine learning models is imperative, yet
challenging. While several approaches have been proposed,
one view towards mitigating bias is through adversarial learning. A discriminator is used to identify the bias attributes such
as gender, age or race in question. This discriminator is used
adversarially to ensure that it cannot distinguish the bias attributes. The main drawback in such a model is that it directly
introduces a trade-off with accuracy as the features that the
discriminator deems to be sensitive for discrimination of bias
could be correlated with classification. In this work we solve
the problem. We show that a biased discriminator can actually be used to improve this bias-accuracy tradeoff. Specifically, this is achieved by using a feature masking approach using the discriminator’s gradients. We ensure that the features
favoured for the bias discrimination are de-emphasized and
the unbiased features are enhanced during classification. We
show that this simple approach works well to reduce bias as
well as improve accuracy significantly. We evaluate the proposed model on standard benchmarks. We improve the accuracy of the adversarial methods while maintaining or even
improving the unbiasness and also outperform several other
recent methods.
View

Harshvardhan Srivastava, Lijin N S, Sruthi S and Tanmay Basu
The eRisk lab at CLEF 2022 had released three different tasks based on the posts of different users over
Reddit, a popular social media. The first task was early detection of signs of pathological gambling.
The second task was the early prediction of depression. The third one was assessing the severity of
eating disorders over social media posts. The BioNLP research group at the Indian Institute of Science
Education and Research Bhopal (IISERB) participated in all three tasks and submitted five runs using five
different text mining frameworks for task 1 and task 2 and four different runs for task 3. The methods
involve different feature engineering schemes and text classification techniques. The performance of
the classical bag of words model, paragraph embedding technique and transformer-based models were
explored to identify significant features from the given corpora. Moreover, we have identified features
based on the biomedical concepts for pathological gambling using Unified Medical Language Systems, a
repository for biomedical vocabularies. Subsequently, we have explored the performance of different
classifiers, e.g., logistic regression, random forest etc. using various such features generated from the
given data. The official results on the test data of individual tasks show that the proposed frameworks
achieve top scores in terms of some of the evaluation techniques, e.g., precision, F1 score, speed etc. for
all three tasks. The paper describes the performance, value and validity of the proposed frameworks for
individual tasks and the scopes for further improvement.
View
Sourav Saha, Dwaipayan Roy, B Yuvaraj Goud, Chethan S Reddy and Tanmay Basu
CLEF SimpleText 2022 lab focuses on developing effective systems to identify relevant passages from a
given set of scientific articles. The lab has organized three tasks this year. Task 1 is focused on passage
retrieval from the given data for a query text. These passages can be complex and hence require further
simplification to be carried out in tasks 2 and 3. The BioNLP research group at the Indian Institute
of Science Education and Research Bhopal (IISERB) in collaboration with two different information
retrieval research groups at IISER Kolkata and ISI Kolkata participated only in Task 1 of this challenge
and submitted three runs using three different retrieval models. The paper explores the performance of
these retrieval models for the given task. We used a standard BM25 model as our first run to identify
1000 relevant passages for each query. Moreover, the passages for each query were ranked based on
their similarity scores generated by the BM25 model. For our second run, we used a BERT (Bidirectional
Encoder Representations from Transformers) based re-ranking method, called as Mono-BERT to further
rank the 1000 passages retrieved by our first run for each query. A pre-trained sequence to sequence
model based re-ranking method, called MonoT5 was used as our third run to reorder the 1000 passages
retrieved by the Mono-BERT model for each query. As the official results of this task are not yet
announced, we cannot explore the performance of our submissions. However, we have manually checked
the retrieved results of many queries for each run, which indicate that the performance improved from
run 1 to run 2 and further to run 3.
View